2024大数据系统架构全解 从知识体系到智能水务应用实战
在数字化转型浪潮中,大数据技术已成为驱动行业创新的核心引擎。本文将系统性地阐述2024年最新的大数据开发知识体系,并以“智能水务系统”为蓝本,深度解析如何构建一个健壮、高效的大数据应用系统。
第一部分:2024大数据开发核心知识体系全景
一个完整的大数据知识体系如同金字塔,自底向上包含以下关键层级:
- 数据基础层:
- 数据源与采集: 掌握结构化数据(MySQL, Oracle)、半结构化与非结构化数据(日志、IoT传感器数据、视频/图像)的采集技术,如Flume, Logstash, Kafka, Sqoop等。
- 数据存储: 深入理解分布式文件系统HDFS、对象存储(如S3/OSS)、NoSQL数据库(HBase, Cassandra, MongoDB)与NewSQL数据库(ClickHouse, TiDB)的选型与应用场景。
- 数据处理与计算层:
- 批处理引擎: 精通Spark Core、Spark SQL(替代传统Hive进行高效ETL),理解MapReduce原理。
- 流处理引擎: 掌握Flink(当前流批一体的主流选择)或Spark Streaming,实现低延迟实时计算。
- OLAP引擎: 熟悉Kylin、Druid、ClickHouse等,支撑快速多维分析查询。
- 数据管理与服务层:
- 数据治理: 涵盖数据血缘、数据质量、元数据管理(Atlas, Datahub)与主数据管理。
- 任务调度: 熟练使用DolphinScheduler、Airflow进行复杂工作流的编排与监控。
- 数据服务与API化: 通过数据中台理念,将数据资产封装为标准化API服务。
- 数据智能与应用层:
- 机器学习/AI框架: 集成Spark MLlib、Flink ML、TensorFlow/PyTorch进行数据挖掘与模型训练。
- BI与可视化: 使用Superset、FineBI、Tableau等工具实现数据洞察。
- 领域应用开发: 将上述能力与具体业务场景(如智能水务)深度融合。
- 运维与云原生层(2024趋势):
- 云原生与容器化: 基于Kubernetes部署和管理大数据组件(如使用Spark on K8s),实现弹性伸缩。
- 运维监控: 全链路监控体系,涵盖Metrics(Prometheus)、Logging(ELK)和Tracing(SkyWalking/Jaeger)。
第二部分:构建智能水务大数据系统应用实战
以“智能水务”为例,我们设计一个从感知到决策的闭环大数据系统。
系统架构设计
- 数据采集层:
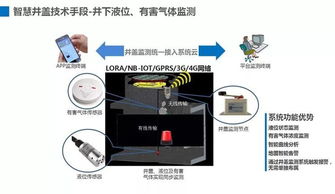
- 物联网感知数据: 通过MQTT协议接入遍布管网的水压、流量、水质(pH值、浊度、余氯)传感器数据,由边缘网关初步处理后,通过Kafka实时上报至数据平台。
- 业务系统数据: 从营收系统(用户缴费)、客服系统(报修工单)、SCADA系统(泵站控制)通过DataX或Canal同步至数据仓库。
- 外部数据: 集成气象数据、地理信息(GIS)数据,为分析提供上下文。
- 数据存储与计算层:
- 实时数据湖: 原始流数据写入Kafka后,一方面通过Flink进行实时处理(如异常检测),另一方面持久化到Iceberg/Hudi格式的数据湖中,实现流批存储统一。
- 数据仓库: 基于Hive/Spark SQL或云上MaxCompute,构建分层模型(ODS->DWD->DWS->ADS),对清洗后的业务数据进行主题域建模(如客户主题、管网主题、营收主题)。
- 实时数仓: 利用ClickHouse或Doris,对实时聚合指标(如区域实时供水量、水质超标告警数)进行亚秒级查询响应。
- 数据处理与分析层:
- 实时处理(Flink作业):
- 泄漏预警: 实时计算管网节点压力与流量模型,偏差超过阈值即时告警。
- 水质实时监控: 对多指标进行流式关联分析,快速定位污染源。
- 批量分析(Spark作业):
- 产销差分析: 每日批量计算供水量与售水量的差值,定位漏损严重区域。
- 用户用水行为画像: 聚类分析不同类型用户(居民、工商业)的用水模式,支撑精准服务与需求预测。
- AI模型训练:
- 用水量预测: 基于历史用水、天气、节假日特征,使用时间序列模型(如LSTM)预测未来用水负荷,指导优化调度。
- 管网健康度评估: 利用图算法与历史维修数据,构建管网脆弱性预测模型。
- 数据服务与应用层:
- 统一数据服务网关: 将分析结果(如预测结果、聚合指标、用户画像标签)通过API对外提供服务。
- 核心应用场景:
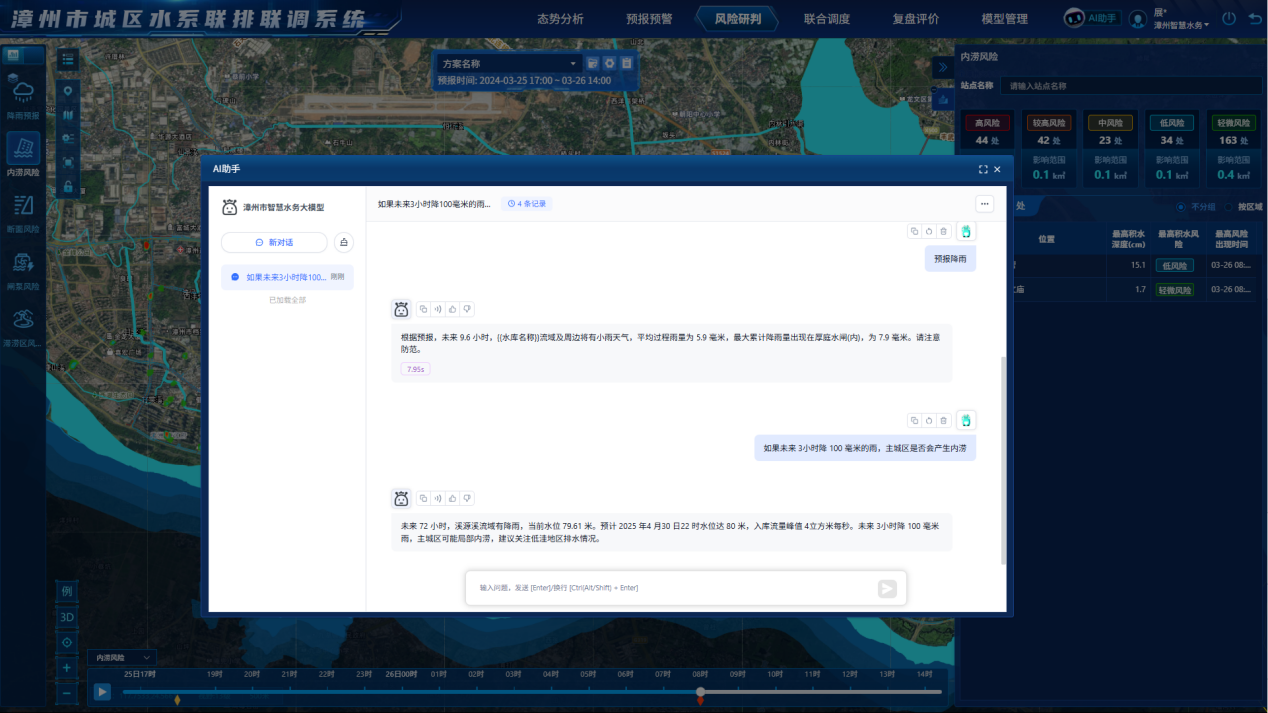
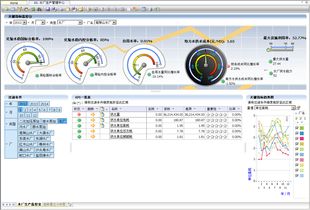
- 调度中心指挥大屏: 基于GIS的可视化大屏,实时展示全网压力、流量、水质及告警信息。
- 移动巡检APP: 向巡检人员推送预警工单、最优巡检路径及历史数据。
- 智慧客服系统: 当用户来电时,自动弹出该区域的停水计划、水质报告及用户画像,提升服务体验。
- 辅助决策报告: 自动生成周期性运营报告,如漏损率分析报告、能耗分析报告。
- 平台保障层:
- 资源管理与调度: 基于YARN或Kubernetes,实现计算资源的弹性分配。
- 安全与权限: 使用Ranger或Sentry进行库、表、列级别的数据权限控制,审计所有数据访问行为。
- 元数据与数据质量: 建立端到端的数据血缘,对关键业务指标(如每日供水量)设置质量校验规则并实时监控。
关键挑战与应对
- 数据质量: 传感器数据存在噪声与缺失,需在流处理环节引入滤波、插值等数据修复算法。
- 实时性与准确性平衡: 泄漏检测模型需在低延迟与高准确率间取得平衡,可采用“流式粗判+批量精核”的混合模式。
- 系统复杂度: 采用微服务架构解耦各子系统,并通过统一的数据平台降低烟囱式开发。
###
构建现代大数据系统,已从单纯的技术堆砌转向以价值为导向的体系化设计。2024年的开发者,需在夯实流批一体、数据湖仓、云原生等核心技术的深刻理解业务领域,如智能水务中的管网物理特性和水务运营知识。唯有如此,才能设计出数据驱动、持续演进、真正创造业务价值的大数据系统架构。本文提供的知识体系与实战案例,旨在为这一旅程提供一份系统性的路线图。
如若转载,请注明出处:http://www.lafxwkeji.com/product/29.html
更新时间:2026-06-18 16:16:32